The PixLab OCR team is pleased to announce that is now fully support scanning India Aadhar ID Cards besides Malaysia (MyKad) and Singapore identity cards as well governments issued Passports from all over the world via the /docscan API endpoint.
When invoked, the /docscan API endpoint shall Extract (crop) any detected face and transform the raw Aadhar ID card content such as holder name, gender, date of birth, ID number, etc. into a JSON object ready to be consumed by your app.
Below, a typical output result of the /docscan API endpoint for a Aadhar ID card input sample:


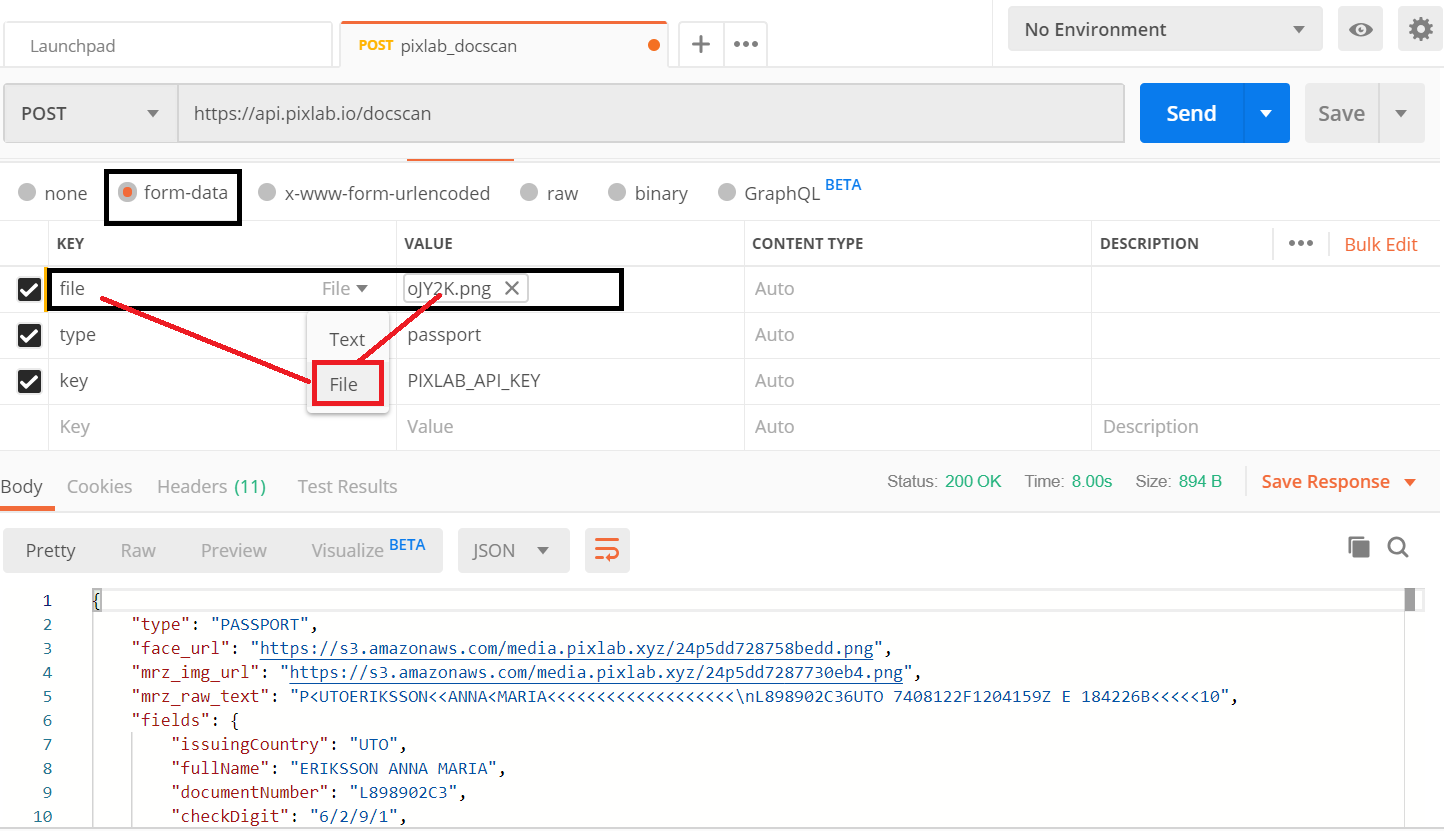
The same API call applies for Passports as well different ID cards from supported countries (you just specify the country name or ISO code):


The code samples used to achieve such result are available to consult via the following Github links:
- Python code for scanning Aadhar ID cards (as well other ID cards from different countries): id_card_scan.py.
- PHP code for scanning Aadhar ID cards: id_card_scan.php.
- Python code for scanning Passports: passport_scan.py.
- PHP code for scanning Passports: passport_scan.php.
- For converting PDF documents to raw images, you can rely on the /pdftoimg API endpoint as shown in this Python or PHP gist.
Face extraction is automatically performed using the /facedetect API endpoint. If you are dealing with PDF documents, you can convert them at first to raw images via the /pdftoimg endpoint.
Finally, the official endpoint documentation is available to consult at pixlab.io/cmd?id=docscan and a set of working samples in various programming language are available at the PixLab samples pages.