A Passport is a document that almost everyone has at some point in their lives. It is issued by the country’s government to its citizens and mainly being used for traveling purposes. It also serves as proof of nationality, name, and more importantly an Universally Unique ID for its owner.
Modern Passport Structure

Many services have been long-time accepting passports as identification documents from their customers to complete their KYC (Know Your Customer) form as required by the legislation in force. This is especially true and enforced for the Finance, HR or Travel sectors. In most cases, a human operator will verify the authenticity of the submitted document and grant validation or reject it.
Things can get really complicated if you have hundreds of KYC forms to checks, but also if your clients differ in nationality. Quickly, you will find yourself drowning in physical copies of passports in different languages that you can not even understand. Let alone the potential legal problems you can face with passport copies laying around the office. This is why, an automated & safe solution for Passports processing is required!
Modern Passport Structure
From the 1980s on wards, most countries started issuing passports containing an MRZ. MRZ stands for the Machine Readable Zone and is usually located at the bottom of the Passport as shown below:
Modern Passport Specimen

Passports that contain an MRZ are referred to as MRPs, machine-readable passports (Almost all modern issued Passports have one). The structure of the MRZ is standardized by the ICAO Document 9303 and the International Electro-technical Commission as ISO/IEC 7501-1.
The MRZ is an area on the document that can easily be read by a machine using an OCR Reader Application or API. It’s not important for you to understand how it works, but if you look at it carefully, you will see that it contains most of the relevant information on the document, combined with additional characters and a checksum that can be extracted programmatically and automatically via API as we will see in the next section.
Once parsed, the following information are automatically extracted from the target MRZ and made immediately available to your app, thanks to the /docscan API endpoint:
- issuingCountry: The issuing country or organization, encoded in three characters.
- fullName: Passport holder full name. The name is entirely upper case.
- documentNumber: This is the passport number, as assigned by the issuing country. Each country is free to assign numbers using any system it likes.
- checkDigit: Check digits are calculated based on the previous field. Thus, the first check digit is based on the passport number, the next is based on the date of birth, the next on the expiration date, and the next on the personal number. The check digit is calculated using this algorithm.
- nationality: The issuing country or organization, encoded in three characters.
- dateOfBirth: The date of the passport holder's birth in YYMMDD form. Year is truncated to the least significant two digits. Single digit months or days are perpended with 0.
- sex: Sex of the passport holder, M for males, F for females, and < for non-specified.
- dateOfExpiry: The date the passport expires in YYMMDD form. Year is truncated to the least significant two digits. Single digit months or days are perpended with 0.
- personalNumber: This field is optional and can be used for any purpose that the issuing country desires.
- finalcheckDigit: This is a check digit for positions 1 to 10, 14 to 20, and 22 to 43 on the second line of the MRZ. Thus, the nationality and sex are not included in the check. The check digit is calculated using this algorithm.
Automatic Passport Processing

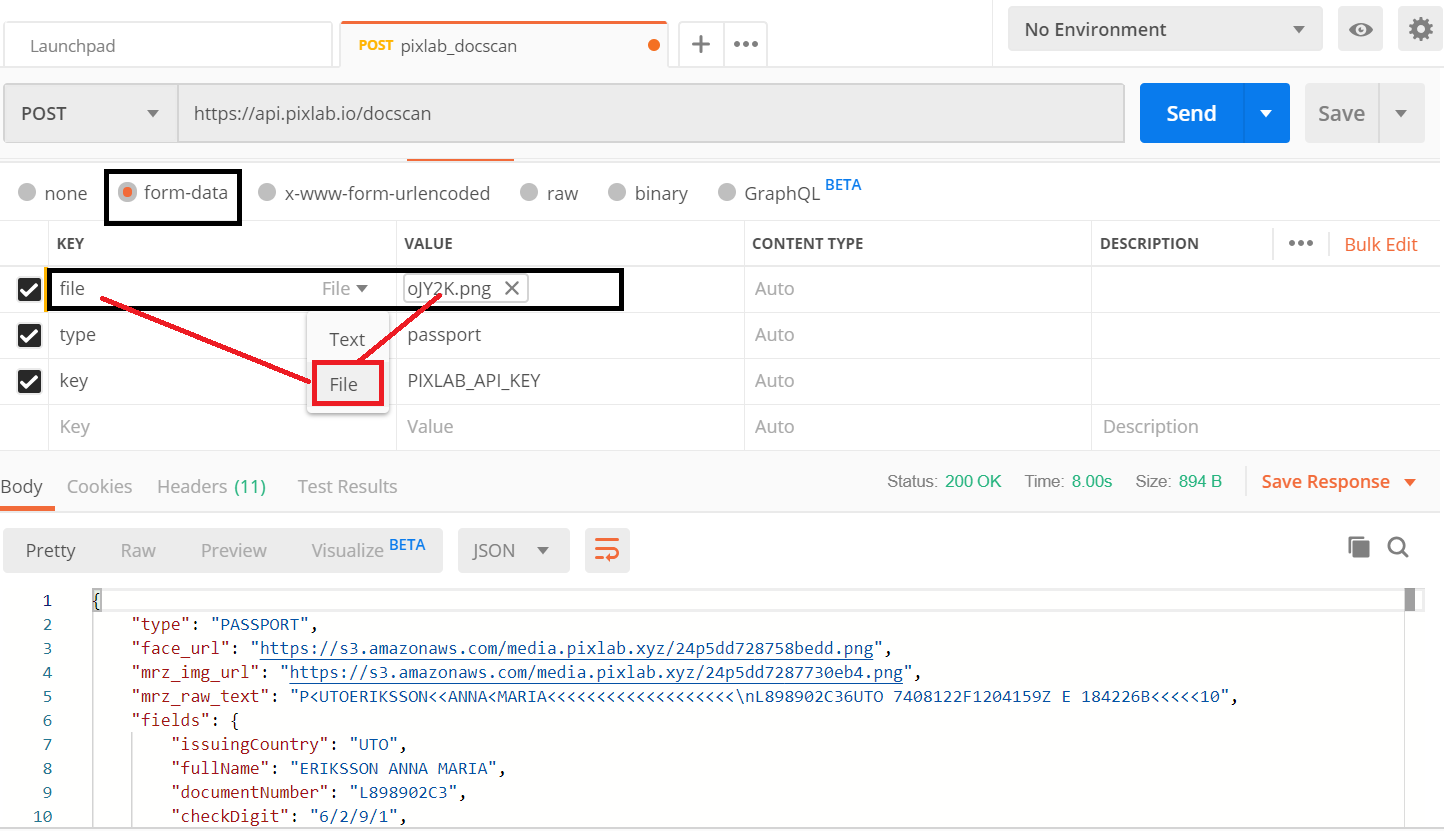
Fortunately for the developer wishing to automate Passports scanning, PixLab can automatically scan & extract passport MRZ but also help to detect possible fraudulent documents. This is made possible thanks to the /docscan API endpoint which let you in a single call scan government issued documents such as Passports, Visas or ID Cards from various countries.
Besides extracting MRZ, the /docscan API endpoint shall automatically crop any detected face and transform binary Machine Readable Zone into stream of text content (i.e. full name, issuing country, document number, date of expiry, etc.) ready to be consumed by your app in the JSON format.
Below, a typical output result of the /docscan endpoint for a passport input image:
Input Passport Specimen (JPEG/PNG/BMP Image)
Extracted MRZ Fields

What follow is the gist used to achieve such result:
Other document scanning code samples are available to consult via the following Github links:
Face extraction is automatically performed using the /facedetect API endpoint. For a general purpose Optical Character Recognition engine, you should rely on the /OCR API endpoint instead. If you are dealing with PDF documents, you can convert them at first to raw images via the /pdftoimg endpoint.
Conclusion
The era we are in is more digitized than ever. Tasks that are repetitive are slowly being replaced by computers and robots. In many cases, they can perform these tasks faster, with a smaller amount of mistakes and in a more cost-effective manner. At PixLab we focus on building software to replace manual repetitive labor in administrative business processes. The processing and checking of passports can be very time-consuming. Using /docscan to automate your passport processing will enable you to save cost, on-board customers faster and reduce errors in administrative processes.