The PixLab Mobile-Hub Team is pleased to announce the release of DocScan, PixLab’s all-in-one mobile document scanner for iPhone and iPad.
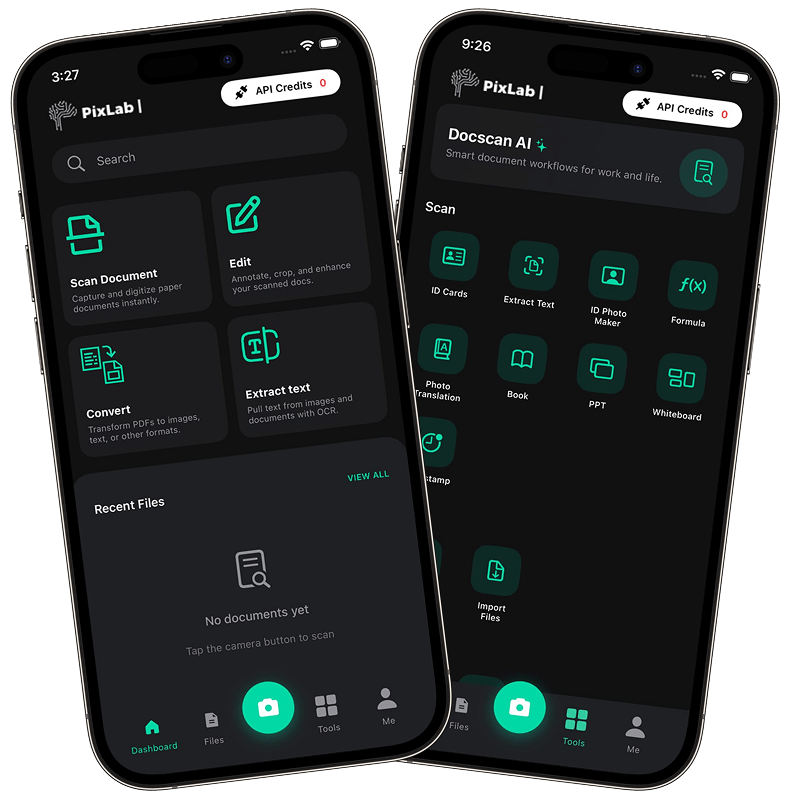
DocScan for iOS is built for people who need more than a basic camera capture. It helps you scan, read, structure, search, and reuse real-world documents directly from your mobile device. Whether you're working with handwritten notes, receipts, invoices, ID cards, menus, signs, or multi-page documents, DocScan for iOS turns raw scans into useful, structured output.
Download DocScan on the App Store
Scan, read, and use your documents faster
Most scanner apps stop after taking a picture. DocScan app goes further by understanding document content and helping you turn it into something actionable.
With DocScan for iOS, you can:
- Scan handwritten notes and turn them into searchable text
- Extract structured data from receipts and invoices
- Capture and enhance ID documents with dedicated scanning tools
- Use built-in document chat to ask questions about scanned pages
- Export results to PDF, Markdown, JSON, and CSV
- Build multi-page documents for archiving, sharing, or downstream workflows
Key features
Two-pass recognition
DocScan uses a two-pass recognition workflow. On-device OCR runs first for speed, then a cloud pass powered by DOCSCAN API improves difficult text when needed. This helps the app handle everything from rushed handwriting to noisy thermal receipts with better reliability.
Built-in document chat
Instead of reading through long pages manually, you can ask questions about what you scanned. Need a summary, a total amount, an expiration date, or a key detail from a contract or receipt? DocScan for iOS helps you get answers faster.
Handwriting scanning
DocScan for iOS is built to handle handwriting that basic OCR often misses, including cursive, shorthand, mixed scripts, and rushed writing. It is especially useful for notes, study material, research pages, and brainstorming sketches.
Receipt and invoice extraction
Thermal receipts and invoices rarely follow one format. DocScan for iOS extracts useful fields like vendor name, dates, totals, taxes, and line items so your scans are ready for accounting, reporting, or automation.
ID document capture
Passports, driver’s licenses, insurance cards, and other important documents need more than a simple photo. DocScan for iOS includes dedicated capture tools with glare reduction, edge detection, contrast tuning, and structured field extraction for cleaner results.
Signs, menus, and everyday document scanning
DocScan for iOS also works well on the go. Scan signs, notices, flyers, menus, and business cards, then search, translate, copy, or save the extracted content.
Flexible export formats
Scanned content should not stay trapped inside an app. DocScan supports export to:
- Markdown
- JSON
- CSV
This makes it easier to archive scans, send them to teammates, move them into spreadsheets, or plug them into internal tools and automated workflows.
Built for real-world use
The DocScan mobile app is designed for people who work with documents every day, including:
- Students and researchers digitizing handwritten notes and study material
- Freelancers and small businesses capturing receipts, invoices, and contracts
- Travelers saving IDs and reading signs or menus abroad
- Developers and integrators building scanning and OCR into their own apps
Powered by the PixLab DOCSCAN API
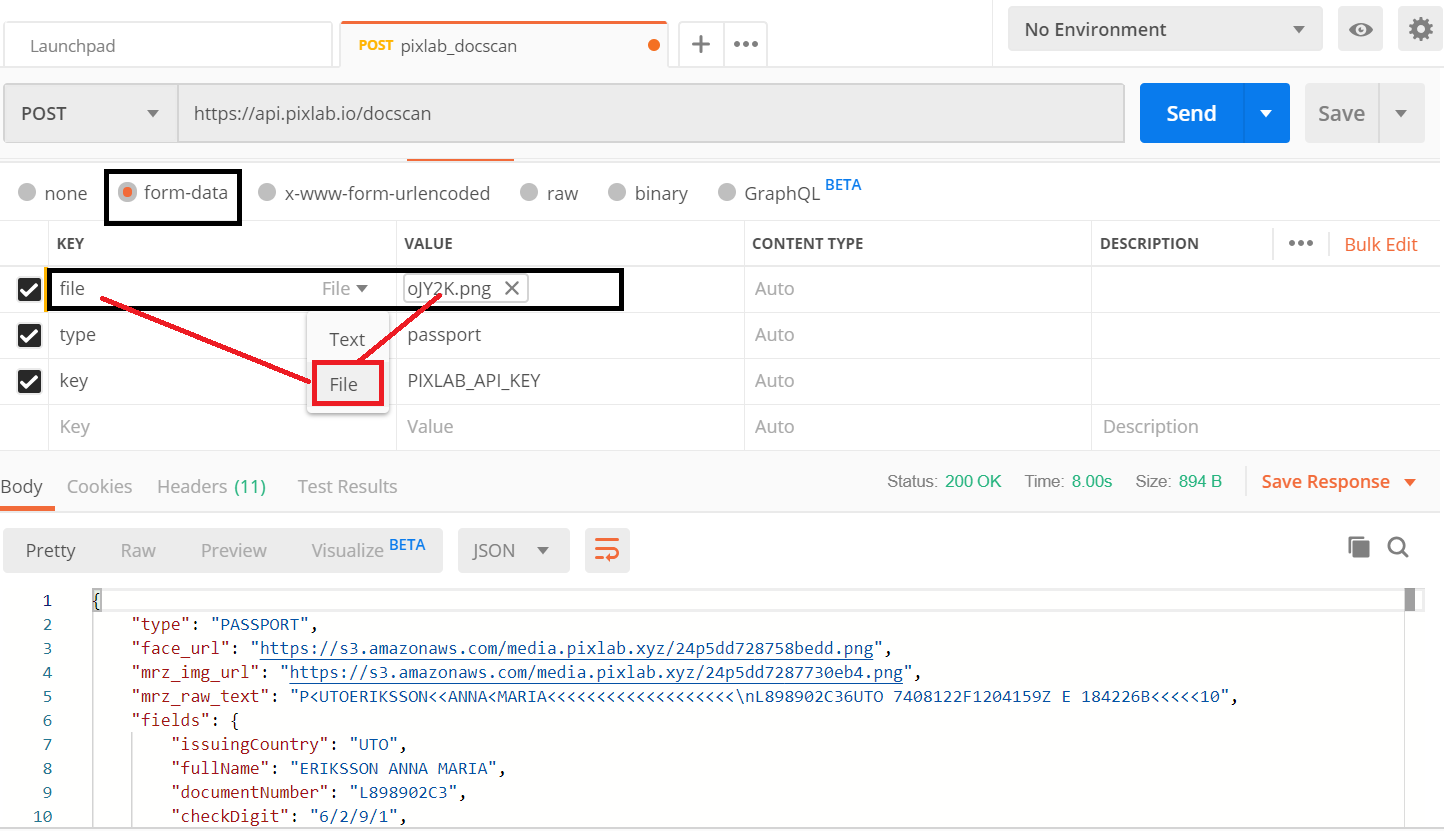
One of the most important things about DocScan for iOS is that its scanning capabilities are powered by the PixLab DOCSCAN API.
That means the same engine behind the mobile app is also available to developers who want to add production-ready document scanning, OCR, KYC extraction, receipt ingestion, and structured document workflows to their own products.
If you’re building your own app, service, or internal platform, you can start integrating the same API that powers DocScan for iOS:
- DOCSCAN API: https://pixlab.io/id-scan-api/docscan
Available now
DocScan for iOS is now available on the App Store for iPhone and iPad.
- Homepage: https://pixlab.io/mobile-apps/docscan-app
- App Store: https://apps.apple.com/us/app/docscan-all-in-one-scanner/id6758423983
We built DocScan for iOS to make mobile document work faster, more intelligent, and more useful from the moment you capture a page. We’re excited to see how users and developers put it to work.