FOR IMMEDIATE RELEASE
![]()
PixLab, a leading provider of advanced image and video analysis solutions, is thrilled to unveil its newly redesigned and highly innovative Machine Learning-based document scanner engine, developed in-house.
This groundbreaking technology is specifically designed for Know Your Customer (KYC) and ID verification tasks, offering customer onboarding solutions that go beyond standard KYC and Anti-Money Laundering (AML) checks. The PixLab DOCSCAN API Endpoint empowers organizations to boost conversions, reduce fraud, and maintain global compliance effortlessly.
The PixLab DOCSCAN API Endpoint revolutionizes the way government-issued documents, including Passports, Visas, U.S Driver License, and ID cards from various countries including but not limited to Malaysia, Singapore, India, and Emirates, are scanned and verified. With a single call, organizations can effortlessly scan and extract critical information from these documents. The API endpoint also features automatic face extraction, enhancing the accuracy and completeness of the scanning process.
Below, the DOCSCAN API endpoint output for a typical Input Passport Image:
Input Passport Specimen (JPEG/PNG/BMP Image or PDF Upload)

And, the extracted Passport (MRZ) Fields

One of the key highlights of the DOCSCAN API endpoint is its ability to transform binary data, such as Passport Machine Readable Zone (MRZ), into a stream of textual content in JSON format. This includes extracting crucial details such as the Full Name, Issuing Country, Document Number, Date of Birth & Expiry, etc.. This seamless integration of the extracted information into your application allows for streamlined and efficient processes, reducing manual effort and eliminating errors.
PixLab takes document scanning and verification to the next level by offering additional features that help identify possible fraudulent documents. The DOCSCAN API endpoint's automated face scanning capabilities, combined with its MRZ extraction functionality, enable developers to automate passport scanning while maintaining stringent security standards. This empowers organizations to protect against fraudulent activities and maintain the integrity of their processes.
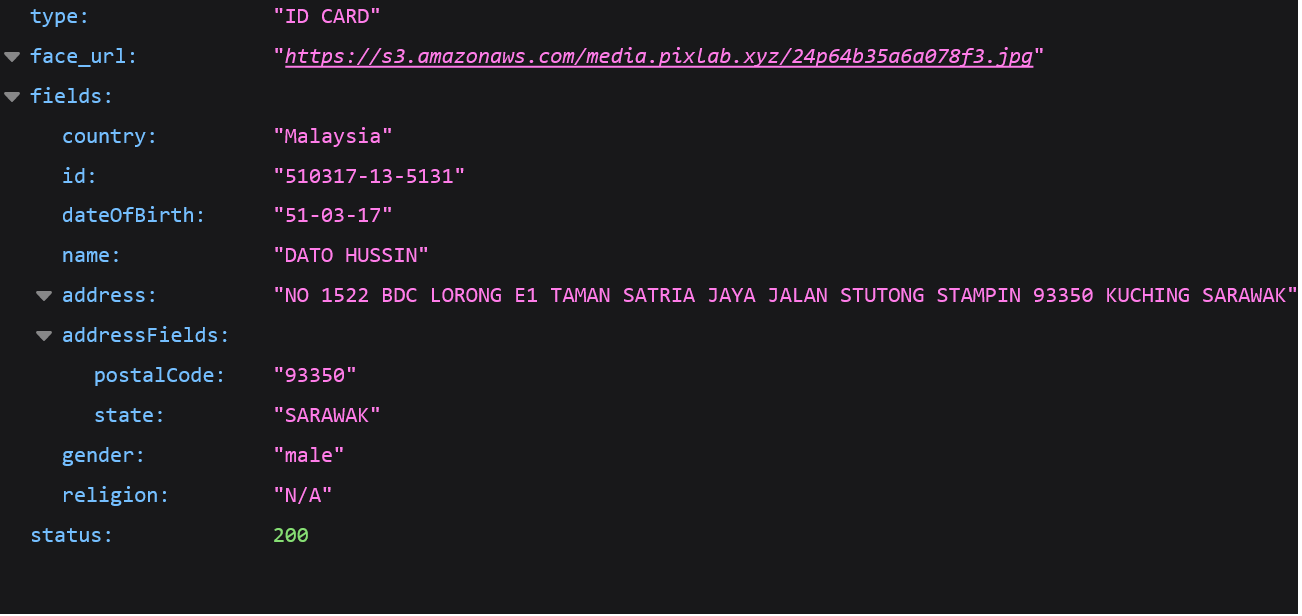
Input ID Card Specimen from Malaysia (MyKAD) (JPEG/PNG/BMP Image or PDF Upload)

And, the extracted MyKAD Fields including Face Extraction, Date Of Birth, Full Name, Address, Religion, and ID Number
In today's increasingly digitized era, the need for automation and efficiency is paramount. Manual and repetitive administrative tasks can be time-consuming, error-prone, and costly. By leveraging the power of the PixLab DOCSCAN API endpoint, organizations can automate passport processing, resulting in substantial cost savings, accelerated customer on-boarding, and enhanced accuracy in administrative processes.
Finally, to learn more about PixLab's DOCSCAN API endpoint and its comprehensive features, please refer to the previous blog posts & code samples:
- Passports, Travel Documents & ID Cards Scan API Endpoint Available
- Full Scan Support for Malaysia and Singapore ID Cards
- Full Scan Support for United Arab Emirates (UAE) ID/Residence Cards
- PixLab’s Document Scanner now able to scan Driving License issued from any U.S. state
- Implement a Minimalistic KYC Form & Identify Verification Check
- Step-by-step guide to do e-KYC in your app
- Streamlining KYC with PixLab Document Scanner API
Code Samples
- Scan a government issued Passport document using the PixLab API. Extract the user's face and display all MRZ fields (PHP Code)
- Scan a government issued Passport document using the PixLab API. Extract the user's face and display all MRZ fields (Python Code)
- Scan Malaysia ID Card (MyKAD) (PHP Code)
- Scan government issued ID card from Malaysia (MyKAD, MyKID)., extract the user face and parse all fields (Python Code)
About PixLab
PixLab is a leading provider of advanced image and video analysis solutions, leveraging state-of-the-art technologies such as Machine Learning and Artificial Intelligence. With a commitment to innovation, PixLab empowers organizations across industries to automate and streamline their image and video processing workflows. The company's robust APIs and developer-friendly tools enable businesses to extract valuable insights, perform accurate face recognition, analyze emotions, detect objects, and much more.

