Kuala Lumpur, Malaysia - In a significant industry recognition, PixLab's Document Scanner has been awarded the title of the top KYC ID Verification provider for MyKAD in Malaysia.
This honor underscores the company's commitment to excellence and its continuous drive to provide the best identity verification solutions in the market.
PixLab's Document Scanner has set itself apart with its cutting-edge machine learning technology, user-friendly interface, and stringent data security measures. Businesses across Malaysia have lauded the product for its accuracy and efficiency, making it the go-to solution for KYC ID verification.
Why PixLab Stands Out
PixLab's Document Scanner has been recognized as the number one KYC ID Verification provider for MyKAD in Malaysia. This accolade is not just a testament to the product's superior technology but also its commitment to ensuring a seamless user experience.
Advanced Technology: Leveraging state-of-the-art machine learning algorithms, PixLab offers unparalleled accuracy in scanning and verifying MyKAD documents. This ensures that businesses can trust the authenticity of the ID being presented, reducing the risk of fraud.
User-Centric Design: Understanding the importance of a smooth user journey, PixLab has designed its scanner to be intuitive. This means quicker onboarding for customers and less friction in the verification process.
Data Security: In today's world, data breaches are a growing concern. PixLab prioritizes user data security, ensuring that all scanned information is encrypted and stored securely.
Related Articles
To learn more about PixLab's DOCSCAN API endpoint and its comprehensive features, please refer to the following articles & code samples:
"We are immensely proud of this recognition," said Mrad Chams, CTO of PixLab. "It reaffirms our dedication to providing the best solutions to our users. We understand the critical role identity verification plays in today's digital landscape, and PixLab strive to offer a product that is both reliable and easy to use".
As PixLab continues to innovate, the industry and its users can expect even more advanced features and enhanced user experience in the future. With its eyes set on global expansion, PixLab is on a trajectory to redefine identity verification standards worldwide.
For more information about PixLab and its award-winning Document Scanner, please visit PixLab's website.
The PixLab Document Scanner, development team is pleased to announce that is now fully support scanning Emirates (UAE) ID & Residence Cards via the /DOCSCAN API endpoint at real-time using your favorite programming language.
When invoked, the /DOCSCAN HTTP API endpoint shall Extract (crop) any detected face and transform the raw UAE ID/Residence Card content such as holder name, nationality, ID number, etc. into a JSON object ready to be consumed by your app.
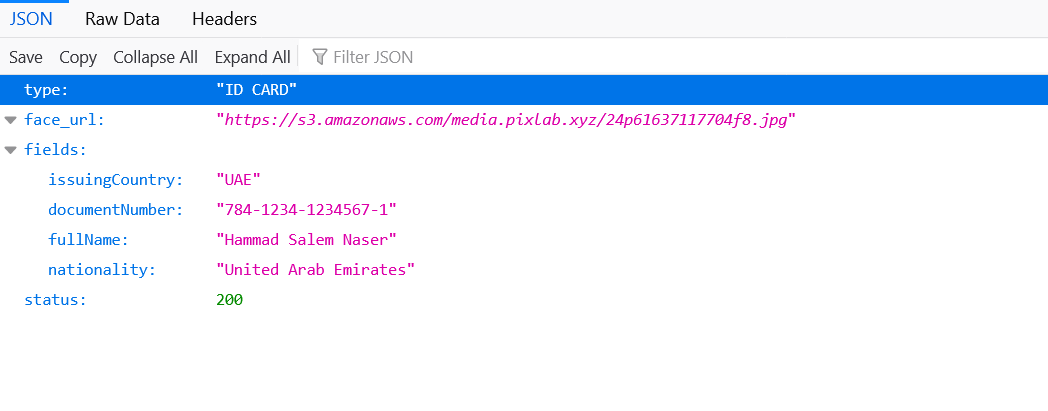
Below, a typical output result of the /DOCSCAN API endpoint for an Emiratis (UAE) ID card input sample:
Input Emirates (UAE) ID Card
Extracted UAE ID Card Fields
The code samples used to achieve such result are available to consult via the following gists:
The same logic applies to scanning official travel documents like Visas, Passports, and ID Cards from many others countries in an unified manner, regardless of the underlying programming language used on your backend (Python, PHP, Ruby, JS, etc.) thanks to the DOCSCAN API endpoint as shown in previous blog posts:
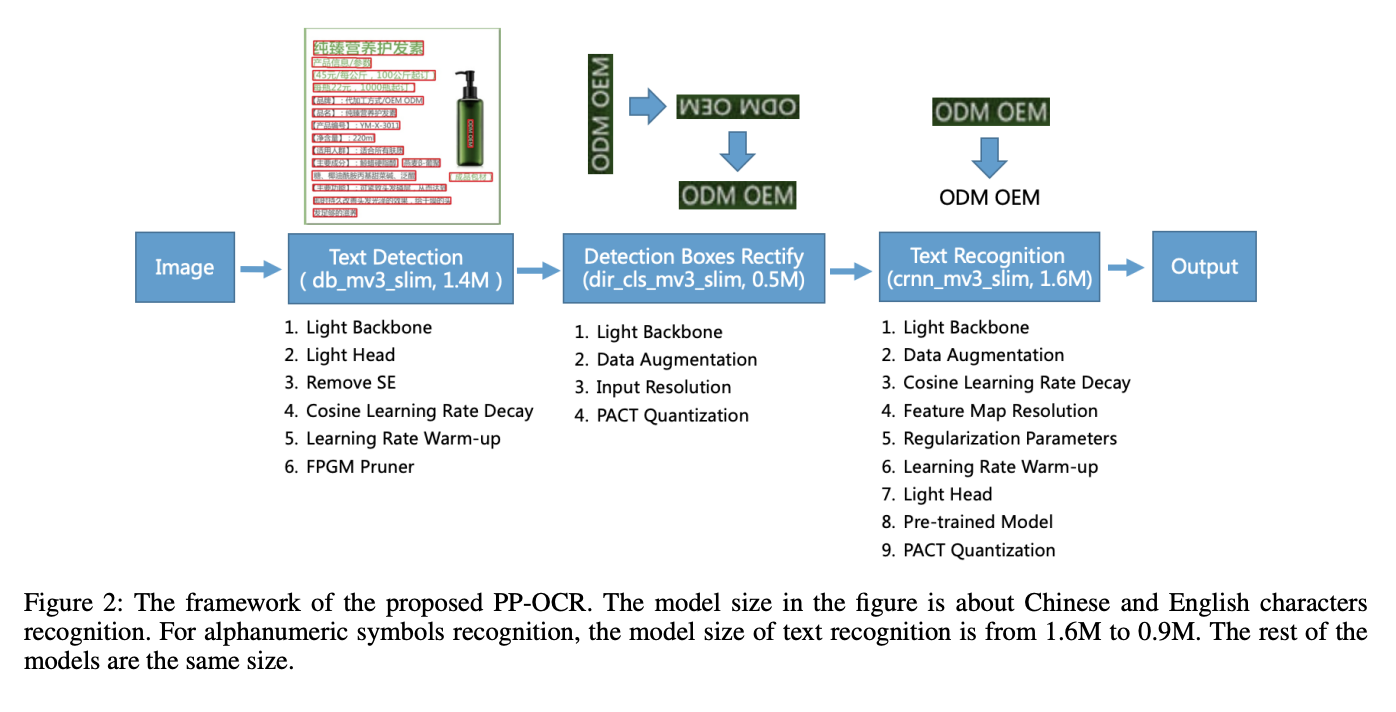
Internally, PixLab's document scanner engine is based on PP-OCR which is a practical ultra-lightweight OCR system, mainly composed of three parts: DB text detection, detection frame correction, and CRNN text recognition. DB stands for Real-time Scene Text Detection.
PP-OCR: A Practical Ultra Lightweight OCR System - Algorithm Overview
The system adopts 19 effective strategies from 8 aspects including backbone network selection and adjustment, prediction head design, data augmentation, learning rate transformation strategy, regularization parameter selection, pre-training model use, and automatic model tailoring and quantization to optimize and slim down the models of each module.
In PP-OCR, Differentiable Binarization (DB) is used as text detector which is based on a simple segmentation network. It integrates feature extraction and sequence modeling. It adopts the Connectionist Temporal Classification (CTC) loss to avoid the inconsistency between prediction and label.
The algorithm is further optimized in five aspect where the detection model adopts the CML (Collaborative Mutual Learning) knowledge distillation strategy and CopyPaste data expansion strategy. The recognition model adopts the LCNet lightweight backbone network, U-DML knowledge distillation strategy and enhanced CTC loss function improvement, which further improves the inference speed and prediction effect.
A Passport is a document that almost everyone has at some point in their lives. It is issued by the country’s government to its citizens and mainly being used for traveling purposes. It also serves as proof of nationality, name, and more importantly an Universally Unique ID for its owner.
Modern Passport Structure
Many services have been long-time accepting passports as identification documents from their customers to complete their KYC (Know Your Customer) form as required by the legislation in force. This is especially true and enforced for the Finance, HR or Travel sectors. In most cases, a human operator will verify the authenticity of the submitted document and grant validation or reject it.
Things can get really complicated if you have hundreds of KYC forms to checks, but also if your clients differ in nationality. Quickly, you will find yourself drowning in physical copies of passports in different languages that you can not even understand. Let alone the potential legal problems you can face with passport copies laying around the office. This is why, an automated & safe solution for Passports processing is required!
Modern Passport Structure
From the 1980s on wards, most countries started issuing passports containing an MRZ. MRZ stands for the Machine Readable Zone and is usually located at the bottom of the Passport as shown below:
Modern Passport Specimen
Passports that contain an MRZ are referred to as MRPs, machine-readable passports (Almost all modern issued Passports have one). The structure of the MRZ is standardized by the ICAO Document 9303 and the International Electro-technical Commission as ISO/IEC 7501-1.
The MRZ is an area on the document that can easily be read by a machine using an OCR Reader Application or API. It’s not important for you to understand how it works, but if you look at it carefully, you will see that it contains most of the relevant information on the document, combined with additional characters and a checksum that can be extracted programmatically and automatically via API as we will see in the next section.
Once parsed, the following information are automatically extracted from the target MRZ and made immediately available to your app, thanks to the /docscan API endpoint:
issuingCountry: The issuing country or organization, encoded in three characters.
fullName: Passport holder full name. The name is entirely upper case.
documentNumber: This is the passport number, as assigned by the issuing country. Each country is free to assign numbers using any system it likes.
checkDigit: Check digits are calculated based on the previous field. Thus, the first check digit is based on the passport number, the next is based on the date of birth, the next on the expiration date, and the next on the personal number. The check digit is calculated using this algorithm.
nationality: The issuing country or organization, encoded in three characters.
dateOfBirth: The date of the passport holder's birth in YYMMDD form. Year is truncated to the least significant two digits. Single digit months or days are perpended with 0.
sex: Sex of the passport holder, M for males, F for females, and < for non-specified.
dateOfExpiry: The date the passport expires in YYMMDD form. Year is truncated to the least significant two digits. Single digit months or days are perpended with 0.
personalNumber: This field is optional and can be used for any purpose that the issuing country desires.
finalcheckDigit: This is a check digit for positions 1 to 10, 14 to 20, and 22 to 43 on the second line of the MRZ. Thus, the nationality and sex are not included in the check. The check digit is calculated using this algorithm.
Automatic Passport Processing
Fortunately for the developer wishing to automate Passports scanning, PixLab can automatically scan & extract passport MRZ but also help to detect possible fraudulent documents. This is made possible thanks to the /docscan API endpoint which let you in a single call scan government issued documents such as Passports, Visas or ID Cards from various countries.
Besides extracting MRZ, the /docscan API endpoint shall automatically crop any detected face and transform binary Machine Readable Zone into stream of text content (i.e. full name, issuing country, document number, date of expiry, etc.) ready to be consumed by your app in the JSON format.
Below, a typical output result of the /docscan endpoint for a passport input image:
Input Passport Specimen (JPEG/PNG/BMP Image)
Extracted MRZ Fields
What follow is the gist used to achieve such result:
Other document scanning code samples are available to consult via the following Github links:
Face extraction is automatically performed using the /facedetect API endpoint. For a general purpose Optical Character Recognition engine, you should rely on the /OCR API endpoint instead. If you are dealing with PDF documents, you can convert them at first to raw images via the /pdftoimg endpoint.
Conclusion
The era we are in is more digitized than ever. Tasks that are repetitive are slowly being replaced by computers and robots. In many cases, they can perform these tasks faster, with a smaller amount of mistakes and in a more cost-effective manner. At PixLab we focus on building software to replace manual repetitive labor in administrative business processes. The processing and checking of passports can be very time-consuming. Using /docscan to automate your passport processing will enable you to save cost, on-board customers faster and reduce errors in administrative processes.
MEMEs are de facto internet standard nowadays. At least, dozen if not hundred of daily top posts on Imgur or Reddit are probably MEMEs. That is, a pop culture image with sarcastic text (always) displayed on Top, Bottom or Center of that image. A lot of web tools out there let you create memes graphically but a few ones actually propose an API for generating memes from your favorite programming language.
In this blog post, we'll try to generate a few MEMEs programmatically using Python, PHP or whatever language that support HTTP requests with the help of the PixLab API but before that, lets dive a little bit into the tools needed to build a MEME generator.
Crafting a MEME API
Building a RESTful API capable of generating memes at request is not that difficult. The most important part is to find a good image processing library that support the annotate operation (i.e. Text drawing). The most capable & open source libraries are the ImageMagick suite and its popular fork GraphicsMagick. Both provides advanced annotate & draw capability such as selecting the target font, its size, text position, the stroke width & height and beyond. Both should be a good fit and up to the task. Here is some good tutorials to follow if you wanna build your own RESTful API:
In our case, we'll stick with the PixLab API due to the fact that is shipped with robust API endpoints such as Image compositing, facial landmarks extraction, dynamic image creation that proves of great help when working with complex stuff such as cloning Snapchat filters or playing with GIFs.
So, without further ado, let's start programming some memes..
Draw some funny text on top & bottom of that image to obtain something like this:
Using the following code:
import requests
import json
# Draw some funny text on top & button of the famous Cool Cat, pubic domain image.
# https://pixlab.io/cmd?id=drawtext is the target command
req = requests.get('https://api.pixlab.io/drawtext',params={
'img': 'https://pixlab.io/images/jdr.jpg',
'top': 'someone bumps the table',
'bottom':'right before you win',
'cap':True, # Capitalize text,
'strokecolor': 'black',
'key':'Pix_Key',
})
reply = req.json()
if reply['status'] != 200:
print (reply['error'])
else:
print ("Meme: "+ reply['link'])
/*
* PixLab PHP Client which is just a single class PHP file without any dependency that you can get from Github
* https://github.com/symisc/pixlab-php
*/
require_once "pixlab.php";
# Draw some funny text on top & button of the famous Cool cat, public domain photo
# https://pixlab.io/cmd?id=drawtext is the target command
/* Target image */
$img = 'https://pixlab.io/images/jdr.jpg';
# Your PixLab key
$key = 'My_Pix_Key';
/* Process */
$pix = new Pixlab($key);
if( !$pix->get('drawtext',array(
'img' => $img,
'top' => 'someone bumps the table',
'bottom' => 'right before you win',
'cap' => true, # Capitalize text,
'strokecolor' => 'black'
)) ){
echo $pix->get_error_message()."n";
die;
}
echo "Pic Link: ".$pix->json->link."n";
If this is the first time you've seen the PixLab API in action, your are invited to take a look at the excellent introduction to the API in 5 minutes or less.
Only one command (API endpoint) is actually needed in order to generate such a meme:
drawtext is the API endpoint used for text annotation. It expect the text to be displayed on Top, Center or Bottom of the target image and support a bunch of other options such as selecting the text font, its size & colors, whether to capitalize the text or not, stroke width & opacity and so on. You can find out all the options the drawtext command takes here.
There is a more flexible command named drawtextat that let you draw text on any desired region of the input image by specifying the target coordinates (X,Y) of where the text should be displayed. Here is an usage example.
Dynamic MEME
This example is similar to the previous one except that the image we'll draw something on top is generated dynamically. That is, we will request from the PixLab API server to create a new image for us with a specified height, width, background color and output format and finally we'll draw our text at the center of the generated image to obtain something like this:
Using this code:
import requests
import json
# Dynamically create a 300x300 PNG image with a yellow background and draw some text on the center of it later.
# Refer to https://pixlab.io/cmd?id=newimage && https://pixlab.io/cmd?id=drawtext for additional information.
req = requests.get('https://api.pixlab.io/newimage',params={
'key':'My_Pix_Key',
"width":300,
"height":300,
"color":"yellow"
})
reply = req.json()
if reply['status'] != 200:
print (reply['error'])
exit();
# Link to the new image
img = reply['link'];
# Draw some text now on the new image
req = requests.get('https://api.pixlab.io/drawtext',params={
'img':img, #The newly created image
'key':'My_Pix_Key',
"cap":True, #Uppercase
"color":"black", #Text color
"font":"wolf",
"center":"bonjour"
})
reply = req.json()
if reply['status'] != 200:
print (reply['error'])
else:
print ("Pic location: "+ reply['link'])
/*
* PixLab PHP Client which is just a single class PHP file without any dependency that you can get from Github
* https://github.com/symisc/pixlab-php
*/
require_once "pixlab.php";
# Dynamically create a 300x300 PNG image with a yellow background and draw some text on top of it later.
# Refer to https://pixlab.io/cmd?id=newimage && https://pixlab.io/cmd?id=drawtext for additional information.
# Your PixLab key
$key = 'My_Pix_Key';
/* Process */
$pix = new Pixlab($key);
echo "Creating new 300x300 PNG image...n";
/* Create the image first */
if( !$pix->get('newimage',[
"width" => 300,
"height" => 300,
"color" => "yellow"
]) ){
echo $pix->get_error_message()."n";
die;
}
# Link to the new image
$img = $pix->json->link;
echo "Drawing some text now...n";
if( !$pix->get('drawtext',[
'img' => $img, #The newly created image
"cap" => True, #Uppercase
"color" => "black", #Text color
"font" => "wolf",
"center" => "bonjour"
]) ){
echo $pix->get_error_message()."n";
die;
}
echo "New Pic Link: ".$pix->json->link."n";
Here, we request a new image using the newimage API endpoint which export to PNG by default but you can change the output format at request. We set the image height, width and the background color respectively to 300x300 with a yellow background color.
Note that if one of the height or width parameter is missing (but not both), then the available length is applied to the missing side and if you want a transparent image, set the color parameter to none.
We finally draw our text at the center of the newly created image using the wolf font, black color and 35 px font size. Of course, one could draw lines, a rectangle for example to surround faces, merge with other images and so forth...
Mimic Snapchat Filters
This last example, although relatively unrelated to our subject here is about to show how to mimic the famous Snapchat filters programmatically. So, given an input image:
and this eye mask:
output something like this:
Well, in order to achieve that effect except for the MEME we draw on the bottom of that image, lots of computer vision algorithms are involved here such as face detection, facial landmarks extraction, pose estimation and so on. You are invited to take a look at our previous blog post on how such filter is produced, what techniques are involved and so on: Mimic Snapchat Filters Programmatically.
Conclusion
Generating MEMEs is quite easy providing a good image manipulation library. We saw that ImageMagick and GraphicsMagick with their PHP/Node.js binding can be used to create your own MEME Restful API.
Our simple yet elegant solution is to rely on the PixLab API. Not only generating MEMEs is straightforward but also, you'll be able to perform advanced analysis & processing operations on your input media such as face analysis, nsfw content detection and so forth. Your are invited to take a look at the Github sample page for dozen of the others interesting samples in action such as censoring images based on their nsfw score, blurring human faces, making gifs, etc. All of them are documented on the PixLab API endpoints reference doc and the 5 minutes intro the the API.
Finally, if you have any suggestion or critics, please leave a comment below.









 and this eye mask:
and this eye mask:

 located at.
located at.  Well, in order to achieve that effect except for the MEME we draw on the bottom of that image, lots of computer vision algorithms are involved here such as
Well, in order to achieve that effect except for the MEME we draw on the bottom of that image, lots of computer vision algorithms are involved here such as {kind=link}