The PixLab Document Scanner, development team is pleased to announce that is now fully support scanning Emirates (UAE) ID & Residence Cards via the /DOCSCAN API endpoint at real-time using your favorite programming language.
When invoked, the /DOCSCAN HTTP API endpoint shall Extract (crop) any detected face and transform the raw UAE ID/Residence Card content such as holder name, nationality, ID number, etc. into a JSON object ready to be consumed by your app.
Below, a typical output result of the /DOCSCAN API endpoint for an Emiratis (UAE) ID card input sample:

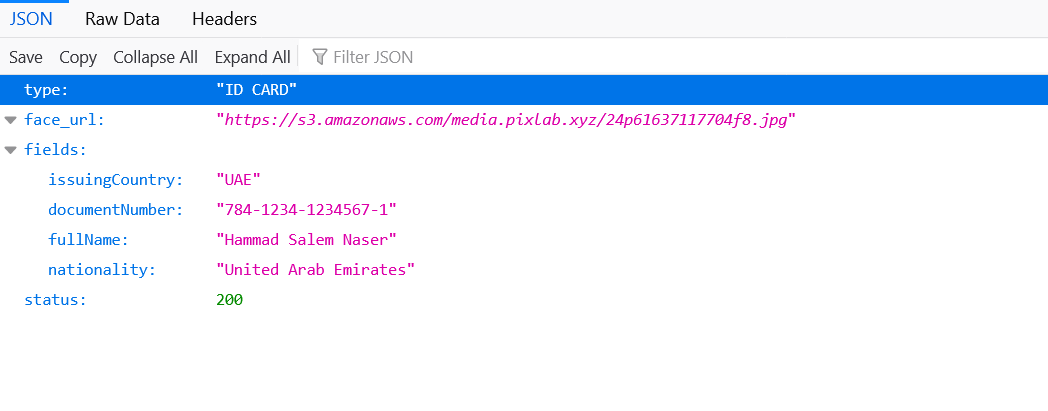
The code samples used to achieve such result are available to consult via the following gists:
- Python Code Samples for Scanning UAE ID Card: uae_emirates_id_card_scan.py
- PHP Code Samples for Scanning UAE ID Card: uae_emirates_id_card_scan.php
- PixLab Github Repository: github.com/symisc/pixlab
The same logic applies to scanning official travel documents like Visas, Passports, and ID Cards from many others countries in an unified manner, regardless of the underlying programming language used on your backend (Python, PHP, Ruby, JS, etc.) thanks to the DOCSCAN API endpoint as shown in previous blog posts:
- Passports & Travel Document Scan: Blog Announcement & Code Sample.
- Malaysia & Singapore ID Card Scan: Blog Announcement & Code Sample.
- Aadhar India ID Card Scan: Blog Announcement & Code Sample.
Algorithm Details
Internally, PixLab's document scanner engine is based on PP-OCR which is a practical ultra-lightweight OCR system, mainly composed of three parts: DB text detection, detection frame correction, and CRNN text recognition. DB stands for Real-time Scene Text Detection.
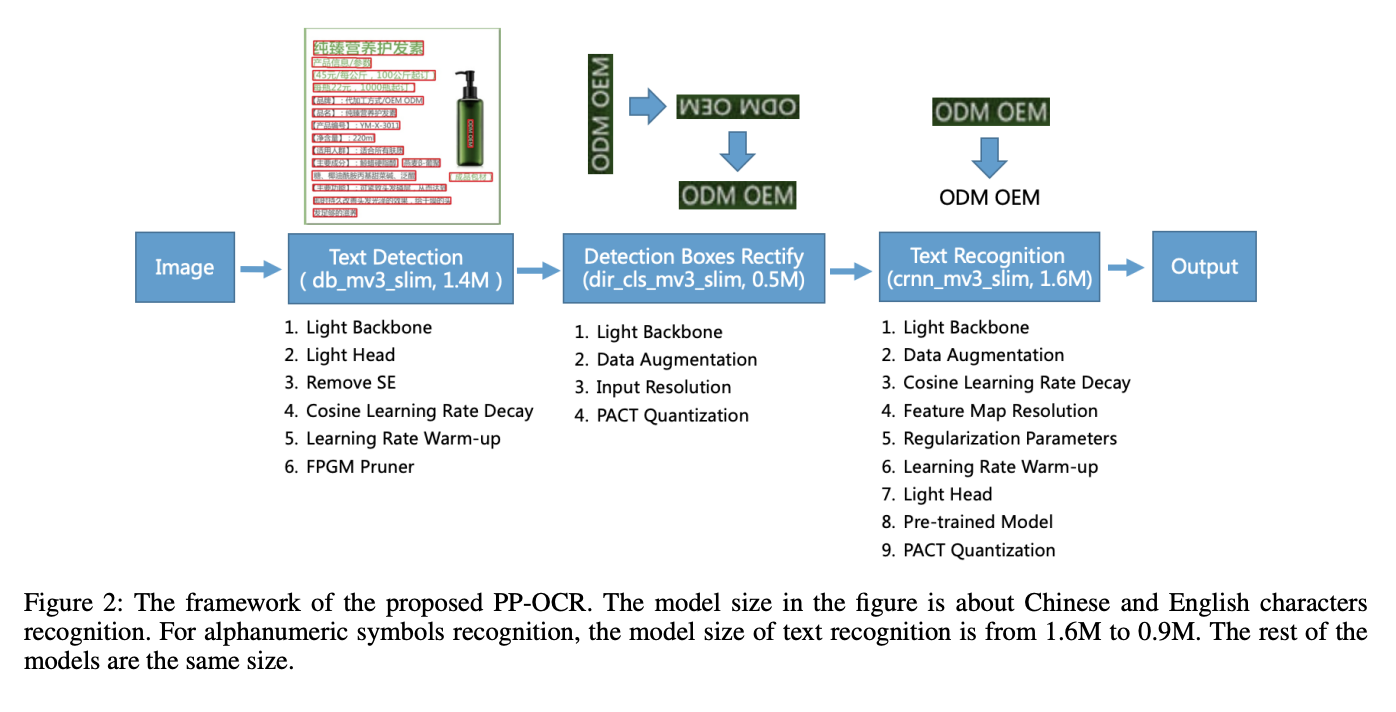
The system adopts 19 effective strategies from 8 aspects including backbone network selection and adjustment, prediction head design, data augmentation, learning rate transformation strategy, regularization parameter selection, pre-training model use, and automatic model tailoring and quantization to optimize and slim down the models of each module.
In PP-OCR, Differentiable Binarization (DB) is used as text detector which is based on a simple segmentation network. It integrates feature extraction and sequence modeling. It adopts the Connectionist Temporal Classification (CTC) loss to avoid the inconsistency between prediction and label.
The algorithm is further optimized in five aspect where the detection model adopts the CML (Collaborative Mutual Learning) knowledge distillation strategy and CopyPaste data expansion strategy. The recognition model adopts the LCNet lightweight backbone network, U-DML knowledge distillation strategy and enhanced CTC loss function improvement, which further improves the inference speed and prediction effect.