At PixLab and Symisc Systems, we build systems that move data between native C++ code and Python-based machine learning workflows. In practice, that often means dealing with NumPy array files.
Today, we are open-sourcing syNumpy, a standalone C++17 library for reading and writing NumPy .npy files.
syNumpy is designed to be simple to integrate, easy to understand, and reliable in production. It gives native applications a clean way to exchange numerical arrays with Python tooling without dragging in a heavy dependency stack.
Why We Built It
In computer vision, facial analysis, visual search, OCR, and document processing, moving tensors and feature vectors across systems is routine. NumPy’s .npy format is a practical interchange format, but using it directly from C++ often means either relying on outdated code, pulling in more infrastructure than needed, or maintaining internal glue code.
We wanted something better:
- modern C++17
- small and focused API surface
- easy vendoring into existing projects
- explicit validation and predictable failures
- production-ready
.npy support without unnecessary complexity
That became syNumpy.
Production-Tested Inside FACEIO and PixLab
syNumpy is not a toy project or a throwaway utility. It is used internally by FACEIO for facial feature extraction workflows and by PixLab / Symisc Systems across production systems tied to visual search, document processing, and identity-document scanning.
That includes internal workflows behind:
That production use shaped the library directly. The goal was not to ship a bloated abstraction layer. The goal was to ship something dependable.
What syNumpy Provides
syNumpy focuses on doing one thing well: reading and writing NumPy .npy arrays from modern C++.
Current highlights include:
- support for NumPy
.npy files
- a standalone C++17 implementation
- a compact API centered around:
syNumpy::NpyArraysyNumpy::loadNpyBuffer()syNumpy::loadNpy()syNumpy::saveNpyRaw()- typed
syNumpy::saveNpy() overloads
- append mode support for compatible arrays
- strict validation of malformed headers and truncated payloads
- explicit runtime failures through
syNumpy::Error
The core parser entry point is syNumpy::loadNpyBuffer(), which makes the library useful in embedded, memory-mapped, or network-driven workflows where the file is already available in memory.
Integration Is Intentionally Simple
One of the main design goals was frictionless integration.
The easiest way to use syNumpy is to add these two files directly to your codebase:
Compile them with your existing C++17 target and you are done.
No service layer. No code generator. No large runtime dependency stack.
The repository also includes a CMakeLists.txt and a simple Makefile, but the direct drop-in path is the intended fast path for most teams.
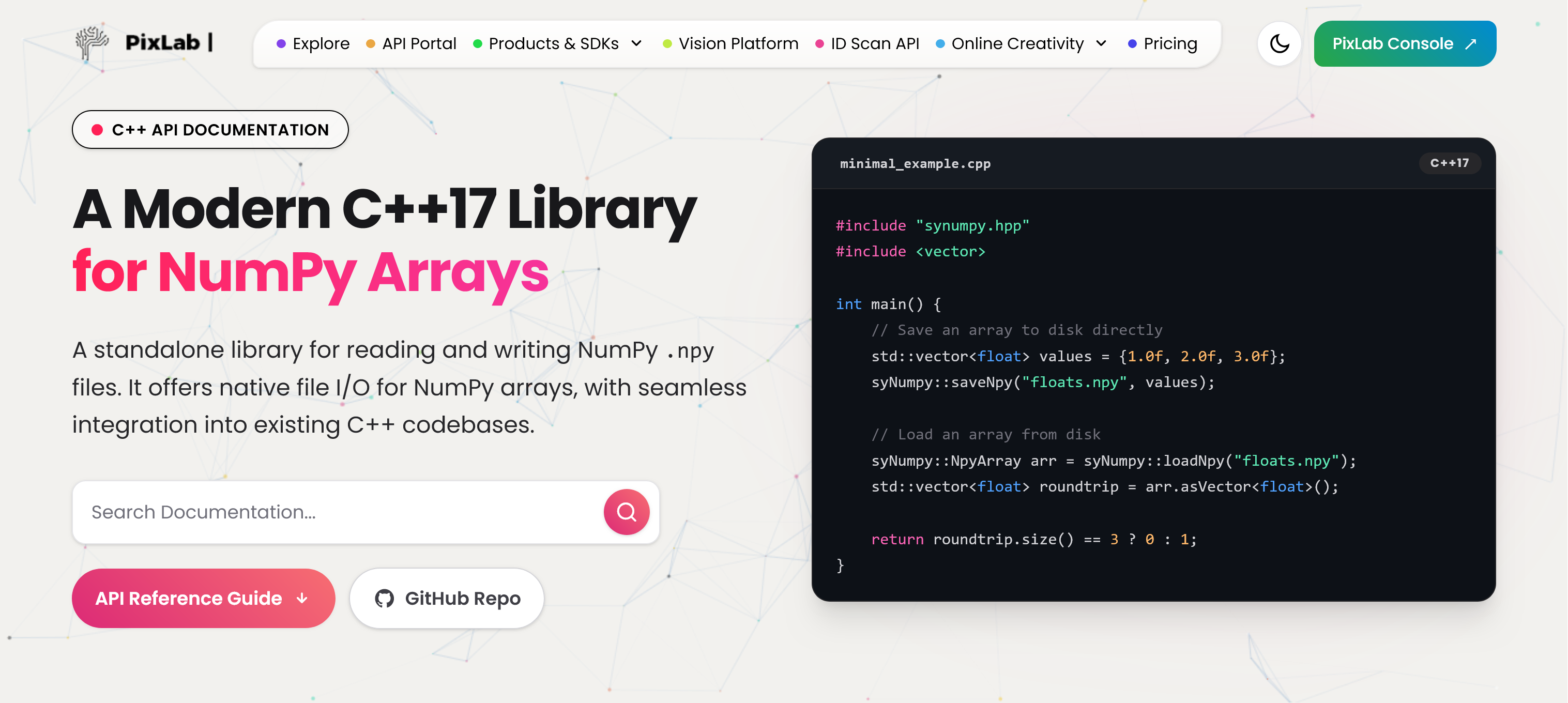
Minimal Example
#include "synumpy.hpp"
#include <vector>
int main() {
std::vector<float> values = {1.0f, 2.0f, 3.0f};
syNumpy::saveNpy("floats.npy", values);
syNumpy::NpyArray arr = syNumpy::loadNpy("floats.npy");
std::vector<float> roundtrip = arr.asVector<float>();
return roundtrip.size() == 3 ? 0 : 1;
}
A Better Fit for Native ML and Vision Pipelines
There is a practical gap between Python-first tooling and production-grade native applications. syNumpy is meant to help close that gap.
If your system is already in C++, but your models, offline tooling, embeddings, or data-preparation steps live in Python and NumPy, having a straightforward .npy bridge matters. That is especially true in machine vision and identity workflows, where performance, reliability, and integration simplicity matter more than abstraction for abstraction’s sake.
Open Source and Licensing
syNumpy is released under the BSD 3-Clause License.
You can explore the project here:
Thoughts
We are releasing syNumpy because it solves a real problem we face in production, and because we think the wider C++ and machine vision community can benefit from a small, modern, well-scoped NumPy .npy library.
If you are building native AI, ML, OCR, document-analysis, or vision systems and need a direct bridge to NumPy arrays, syNumpy is built for exactly that use case.
